
笔者结合自己的项目经验,分析了内容APP如何通过给文章分类以及打标签?

17年-18年底我参与了一个资讯内容兴趣偏好标签的项目。什么是内容兴趣偏好标签呢?
简单来说就是分析用户喜欢看的文章类型,得到用户的兴趣偏好,在这样的基础上,对用户进行内容的个性化推荐和push推送,来有效促进app的活跃并拉长用户生命周期。
这件事情简单来说其实就是两步走:
- 一是,给文章进行分类,也就是我们俗称的给文章打标签。
- 二是,给用户打标签,也就是用户阅读了哪些类型的文章,相应的就会获取到自己的兴趣偏好标签。比如我爱看科技类型的文章,那我便有极大的可能被打上科技的资讯标签。整体流程如下;
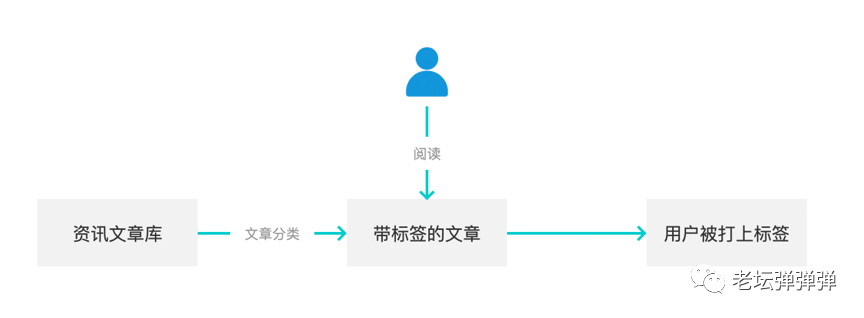
那么在实际操作中真的如此简单吗?看似简单的两个环节,究竟是如何实现的呢?
首先我们来聊一聊给文章进行分类
笔者因为这个项目的原因,看了非常多竞品app的文章分类,发现基本上趋于一致,但也有一些细节上的差异,更多的问题,在于资讯文章的分类很难穷尽,我们参考了市面上已有的分类,并结合一些资料制定了一整套内容兴趣偏好体系,在指定分类时,我们遵循MECE原则,基本达到了相互独立完全穷尽。
接下来,我们要对文章进行分类,我们采用了分类算法的有监督的学习。理想情况下,流程是这样的:
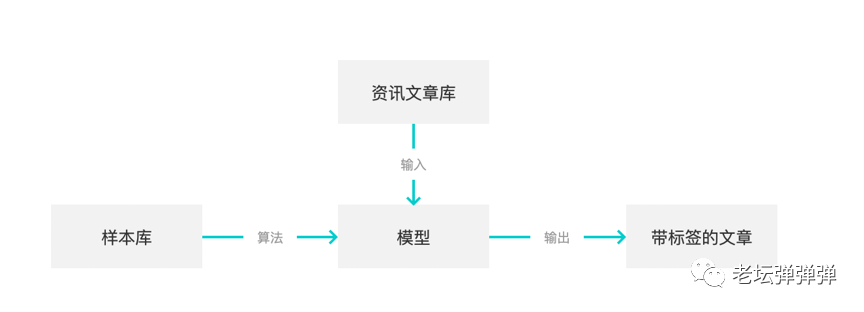
但在实际中面临两个问题,由于选择了有监督的学习,就面临必须要提供有标注的样本的基础。一般情况下有三种方式获取样本:
- 一是人工对文章进行标注,优点是准确,缺点是效率低,对于算法要求大量样本的要求,成本非常高。
- 而另一种方式则是通过一些开源网站提供的关键词进行模型训练,比如可以从搜狗词库获取,优点是成本低,但缺点也很明显,由于不同的分类体系对部分分类的理解不一致,导致分类并不够准确,后期需要耗费大量的人力进行矫正。
- 第三种方式是和一些资讯类app进行合作,获取他们的文章以及分类作为样本,例如目前做的比较好的如今日头条、uc等都是不错的选择。我们当时其实都尝试了(一把辛酸泪)。
获取样本以后,就是算法模型的训练及其检验了。算法模型的训练原理,即通过对样本文章进行分词,抽取实体,建立特征工程,将每一个特征词作为向量,拟合出一个函数,这样,当有新的文章时,该文章通过分词,并通过模型计算出结果。但模型并不是能够有样本一次性就能准确的,模型还需要进行测试和矫正。一般测试流程如下:
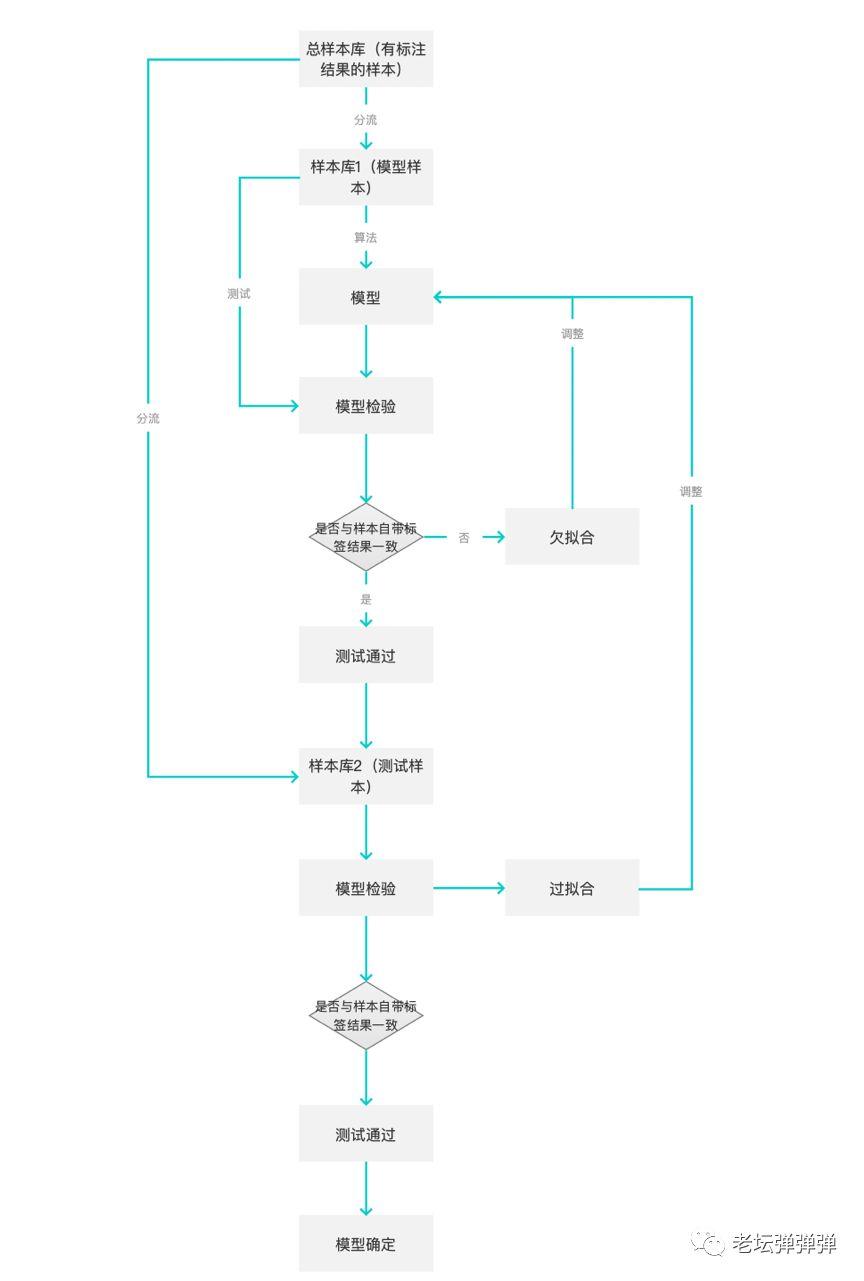
通过了测试的模型也并不是一劳永逸的,仍然可能在后期出现一些分类不准确的问题,这可能是样本造成的,也可能是算法模型造成的。这需要我们找出这些异常的文章及其分类,并矫正分类,再次作为训练样本投喂给模型,进行模型的矫正。一方面,我们可以对转化率比较低的分类的文章进行人工抽检,确定问题是否出在算法。另外,在这里,由于每一篇文章的标签都被赋予了一个值,我们可以为这些值设置一个阈值,当最高值低于某个阈值,这些文章及其标签将被召回,由人工进行标注和矫正,并在此投入样本库中。
文章标签的计算,由于文章具有多种标签的可能,并非一些二分类非此即彼的结果,因此我们采用的方式是,通过相似性算法,模型计算出文章的标签,并赋值,值越高则说明和这类标签越接近,并被打上相应标签。
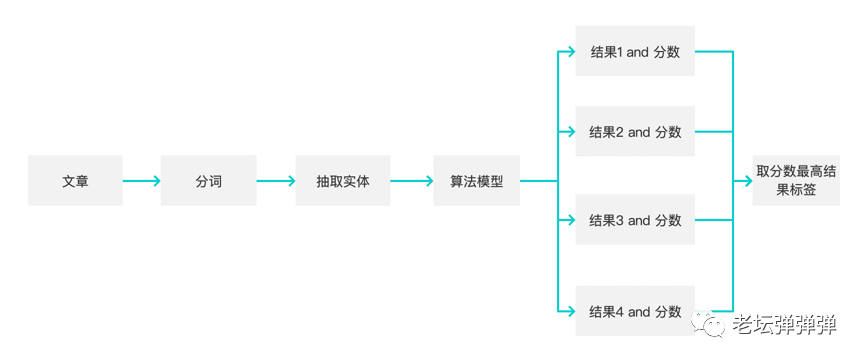
至此,文章打标签的部分就已经完成了。
如何给用户打标签
给用户打标签的方式其实也可以包含两种,统计类的打标签及算法类的打标签。
- 统计类相对简单粗暴式的以用户一段时间阅读的文章类型作为用户的兴趣偏好。
- 而算法类则会增加更多的影响因素,包括文章阅读的数量,阅读的时间间隔,文章与当前热点事件的关系、用户属性因素等等。
前者在算法资源不足同时运营需求量大的情况下可以先行,而后者可以在前者的基础上切分一部分流量对算法模型进行验证和调整,不断优化。
但在用第一种方式进行时我们发现,用户在一段时间内阅读的文章类型并不是稳定的,大部分用户会有一个或者几个主要的兴趣偏好,这些类型阅读的文章篇数会更多,但同时,用户也会或多或少的阅读一些其他类型的文章,甚至有些用户是看到哪里算哪里,什么都会看。
基于这样的情况,我们需要对用户的兴趣偏好进行排名,即通过对用户一段时间内每种文章类型阅读的文章数进行排名,并取用户top 10的标签,清晰告诉运营用户喜欢什么类型的文章,这些类型中,用户喜欢类型的优先级是怎样的,便于运营同学进行推送选择。
因此,用户的标签也需要更加灵活,能够让运营同学基于事件发生时间及事件发生次数等权重进行灵活组合选择用户群。
由于目前push推送很大一部分是由人工进行的,从选择文章,到选择用户,到文章和用户的匹配,在正式进行推送前一般都会进行大批量的A/B test ,而资讯文章的类型非常多,仅一级标签已经达到30+种,二级标签从100到几百不等,总体的标签极有可能会有成千的标签,单靠运营同学进行推送,是绝对无法完成的。
因此,在运营资源有限又无法实现自动化的的情况下一般运营同学会对标签进行测试,并选择其中覆盖用户量大且转化率较高的标签。但同时这样的情况就会导致部分兴趣偏好比较小众的用户被排除出推送的人群。
针对这样的情况,我们取了用户top 10的二级标签及其对应的一级标签作为用户的一级和二级标签。这样,解决了用户覆盖量的问题,也可以让运营人员集中精力对主体标签及人群进行推送。
但同时,另一个问题又出现了,选择用户一段时间内的行为,那么这个一段时间究竟是多长会更加合适,使得既达到能充分反应用户兴趣,同时又覆盖到更多的人群(每天都会有流失的用户,因此时间线越长覆盖用户量越大,时间线越短覆盖用户量越少)
我们发现,用户长期的兴趣偏好趋于某种程度的稳定,但短期的兴趣偏好却又反应了用户短期内跟随热点的行为。因此从这个层面来看,短期可能更能满足用户的需求,但短期覆盖用户量小。在这里,始终有覆盖量和转化率之间永恒的矛盾。
我们的方式是,对用户根据浏览时间进行分段。赋予用户长期兴趣偏好和短期兴趣偏好,并优先短期兴趣偏好,从长期兴趣偏好中则将短期兴趣用户进行排除,进行不同的推送。而对于流失用户,极有可能在最近3个月(资讯当时定义流失用户时间为3个月)没有任何访问记录,针对于这样的用户,我们取用户最后一次有记录的标签作为用户标签,并进行流失挽回。
至此,所有的用户也都有了属于自己的标签,而运营同学也可以根据用户的活跃时间以及阅读的频率对不同的用户进行不同的文章推送,真正的实现千人千面。
在这个问题上我们可以说是踩了不少的坑。
而第二种方式,是通过算法直接为用户打上标签,除了时间和阅读频次,在算法模型中还可以增加更多的特征纬度,比如用户阅读文章距离现在的时间、阅读文章的时长、评论、点赞等等,同时,还可以针对于热点文章、热点事件,降低文章的权重。
结语
当我回首去总结这一段经历的时候,甚至当读者你跟随我去了解这一段经历的时候可能会觉得其实很简单,但是,在这一段经历中我们真的踩了无数的坑,尤其是我们不仅仅要去采集数据、制作标签,甚至还要去指导业务进行投放以及问题分析,那段经历可以说是痛苦并快乐的——
痛苦是因为问题实在太多,业务每天都在追着我问今天为什么转化率又低了;快乐是因为我们最终转化率终于提高了一倍不止,甚至高于行业水平,也算是最好的回报了。
本文由 @糖糖是老坛酸菜女王 原创发布于人人都是产品经理,未经作者许可,禁止转载。
题图来自Unsplash,基于CC0协议。